Billing is an integral part of day to day AWS account operation, and to most it seems like a chore, however there is a lot to be learnt interacting with AWS Billing data.
So why would you ever want to dive into AWS Billing data in the first place?
- It is pretty easy for both novices, and experience developers to rack up a sizable bill in AWS, part of the learning experience is figuring out how this happened.
- The billing data itself is available in parquet format, which is a great format to query and dig into with services such as Athena.
- This billing data is the only way of figuring out how much a specific AWS resource costs, this again is helpful for the learning experience.
- The Cost Explorer in AWS is great if you just want an overview, but having SQL access to the data is better for developers looking to dive a bit deeper.
- The billing service has a feature which records
created_byfor resources, this is only available in the CUR data. If you have already you can enable it via Cost Allocation Tags.
These points paired with the fact that a basic understanding of data wrangling in AWS is an invaluable skill to have in your repertoire.
Suggested CUR Solution
I have put together an automated solution which uses AWS CloudFormation to create a Cost and Usage Reports (CUR) in your billing account with a Glue Table enabling querying of the latest data for each month in Amazon Athena. This project is on github at https://github.com/wolfeidau/aws-billing-store, follow the README.md to get it setup.
In summary it deploys:
- Creates the CUR in the billing service and the bucket which receives the reports.
- Configures a Glue Database and Table for use by Athena.
- Deploys a Lambda function to manage the partitions using Amazon EventBridge S3 events.
Once deployed all you need to do is wait till AWS pushes the first report to the solution, this can take up to 8 hours in my experience, then you should be able to log into Athena and start querying the data.
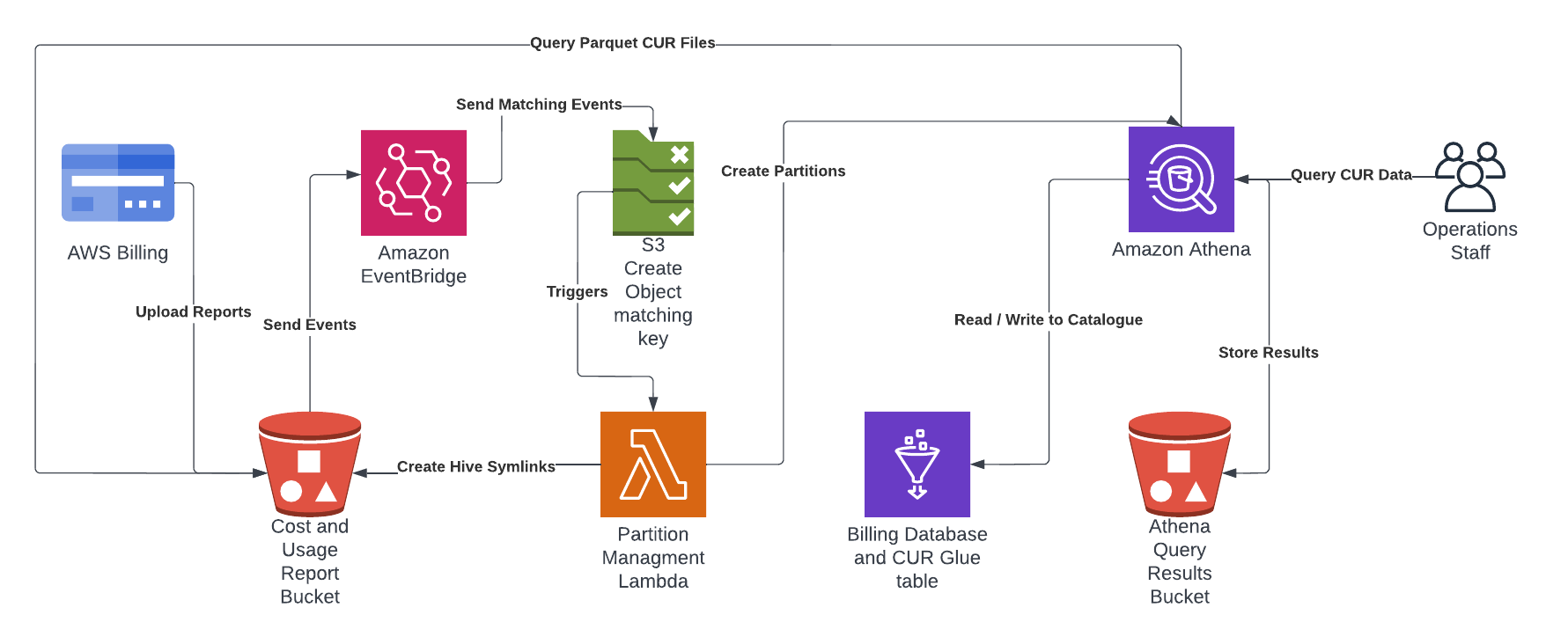
One thing to note is designed to be a starting point, I have released it under Apache 2.0 license so your welcome to pull this solution apart and integrate it into your environment.
Next Steps
To test the solution you can start with a query which shows you AmazonS3 costs grouped by bucket name and aggregated using sum.
SELECT line_item_resource_id as bucket_name,
round(sum(line_item_blended_cost), 4) AS cost,
month
from "raw_cur_data"
WHERE year = '2022'
and month = '7'
AND line_item_product_code = 'AmazonS3'
GROUP BY line_item_resource_id,
month
ORDER BY cost DESC;
There are some great resources with other more advanced queries which provide insights from your CUR data, one of the best is Level 300: AWS CUR Query Library from the The Well-Architected Labs website.
The standout queries for me are:
- Amazon GuardDuty - This query provides daily unblended cost and usage information about Amazon GuardDuty Usage. The usage amount and cost will be summed.
- Amazon S3 - This query provides daily unblended cost and usage information for Amazon S3. The output will include detailed information about the resource id (bucket name), operation, and usage type. The usage amount and cost will be summed, and rows will be sorted by day (ascending), then cost (descending).
Cost Allocation Tags
The Cost Allocation Tags in billing allows you to record data which is included in the CUR. This is a great resource for attributing cost to a user, role or service, or alternatively a cloudformation stack.
I enable the following AWS tags for collection and inclusion in the CUR.
aws:cloudformation:stack-nameaws:createdBy
I also enable some of my own custom tags for collection and inclusion in the CUR.
applicationcomponentbranchenvironment
You can see how these are added in the https://github.com/wolfeidau/aws-billing-store project Makefile when the stacks are launched.